
目錄
前陣子在用 SQL 整理資料,為了放到 Tableau 引用,我寫了一支長達數百行的查詢。我的背景是財務,雖然在工作中常會使用 SQL 整理資料,但並非程式背景,所以也是邊寫邊學。
我用了 4 段 UNION ALL 來拼接不同月份與版本的資料,每一段邏輯相近,只是條件略有不同:
- 第一段:歷史值資料需要簡化整合。
- 第二段:前一季歷史值需要更細的資料解析。
- 第三段:當季估計值(其中部分月份可能為歷史值),需要更細的資料解析。
- 第四段:未來估計值不需太細,仍以簡化整合為主。
此外,估計資料會有多個版本,因此需要呈現多個版本;而歷史值只需一個版本。
結果:
- 查一次主表要跑 30 秒以上
- SQL 又長又難閱讀
- 每次修改或調整欄位,都得在 4 段程式中各確認一次
後來主管建議我用 INNER JOIN 改寫。雖然他幫我改了一小段,但距離最終想要的成果還有差距——師父引進門,修行在個人。我試著改了許久仍不理想,只好一步一步請教 Cursor、ChatGPT 兩位「程式高手」,請他們指出我在改寫上的盲點。最後把整段邏輯改寫成 CTE(Common Table Expression)+ INNER JOIN 的架構:查詢時間從 30 秒 → 6 秒,程式碼長度也減少了一半。
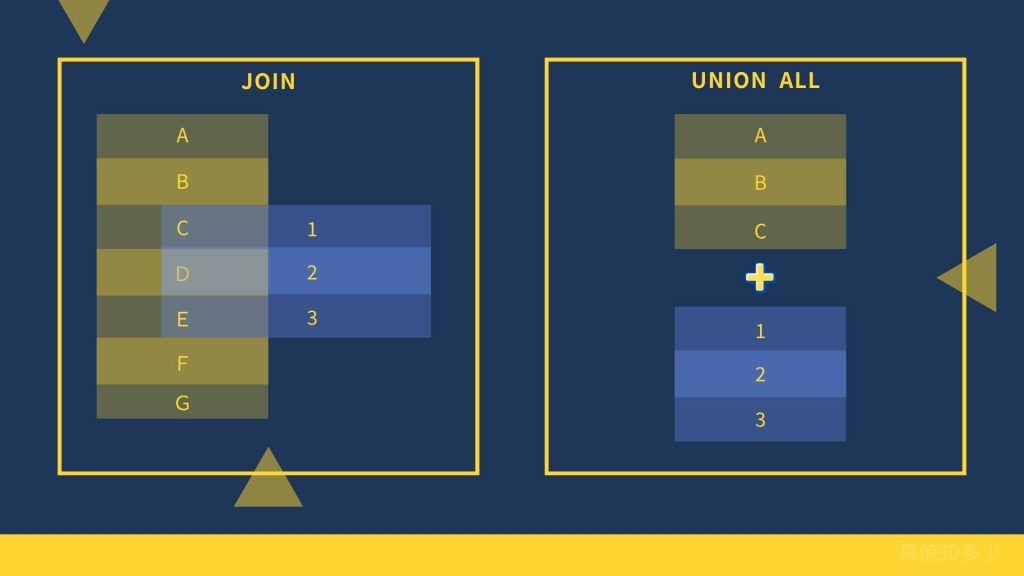
從這次的過程中,這讓我重新體會到:「JOIN」與「UNION」之間,不只是語法選擇,而是一種資料思維的轉換。
概念差異:JOIN vs. UNION ALL
| 類別 | INNER JOIN | UNION ALL |
|---|---|---|
| 用途 | 把兩張表橫向整合 依條件匹配欄位 | 把多個查詢縱向合併 欄位結構需相同 |
| 說明 | 「拼圖」橫向接起來: 兩張表「並排」後對齊合併 | 「積木」縱向疊上去: 兩張表「堆疊」起來 |
| 典型應用 | 整合主表與維度表、 對應規則、補欄位 | 合併不同期間、 分區或來源的資料 |
| 效能特性 | 掃描主表一次即可 | 每段 UNION 都會掃主表一次 |
簡單說:
- JOIN 是「橫向整合」
- UNION 是「縱向拼接」
簡易例子比較:同樣的需求,不同寫法
原始寫法(UNION ALL)
SELECT * FROM sales WHERE month='2025-01'
UNION ALL
SELECT * FROM sales WHERE month='2025-02'
UNION ALL
SELECT * FROM sales WHERE month='2025-03';問題:
- 每段都會掃一次
sales表 - 若表有 500 萬筆資料,就是掃三次
- 結果雖然正確,但效能極差
優化寫法(INNER JOIN 規則表)
WITH month_rule AS (
SELECT unnest(ARRAY['2025-01','2025-02','2025-03']) AS month
)
SELECT s.*
FROM sales s
INNER JOIN month_rule r
ON s.month = r.month;好處:
- 主表
sales只掃一次; - 查詢邏輯集中,可動態調整月份;
- JOIN 在執行計畫中能使用索引與 Hash Join,加速比 UNION ALL 明顯。
效能比較(實際觀察)
| 指標 | UNION ALL | INNER JOIN |
|---|---|---|
| 主表掃描次數 | 3 次(每段一次) | 1 次 |
| 執行時間(500萬筆×3月) | 約 30 秒 | 約 6 秒 |
| SQL 長度 | 約 150 行 | 約 60 行 |
| 維護性 | 每加新月要改程式 | 規則表自動更新即可 |
為什麼 JOIN 比 UNION ALL 快?
重點在於 I/O(Input / Output)。
- UNION ALL → 每段都重掃主表 → 多次 I/O
- INNER JOIN → 主表只掃一次,用條件表控制 → 減少 I/O 次數
換句話說,JOIN 的關鍵效能優勢在於「減少重覆讀取資料」。
何時使用 UNION ALL?
情況 1:
完全不同的資料來源
SELECT * FROM table_A WHERE condition_A
UNION ALL
SELECT * FROM table_B WHERE condition_B -- 不同的表
情況 2:
邏輯完全不同,無法⽤ CASE WHEN 表達
SELECT complex_logic_A(...) FROM table_X
UNION ALL
SELECT complex_logic_B(...) FROM table_X -- 邏輯差異太⼤何時使用 INNER JOIN?
情況 1:
同⼀張表,只是不同的篩選條件
情況 2:
需要根據某個維度表來篩選或聚合資料
情況 3:
可以⽤ CASE WHEN 來表達不同的業務邏輯什麼是 CTE?在這段程式中的用途?
CTE(Common Table Expression)就是在 WITH 區塊裡先定義「暫時的命名結果集合」,後面的查詢可以像表一樣去引用它。架構正確:用 CTE 把「規則→版本→展開→篩選」拆清楚,主表只掃一次。
好處是:
- 模組化:把「規則」分開寫,邏輯一目了然。
- 可維護:改規則只動上游 CTE;下游引用不變。
- 避免主表重掃:在 CTE 把「要取什麼版本」先算好,主查詢只掃一次主表並做聚合。
如同以下程式中的WITH
WITH month_rule AS (
SELECT unnest(ARRAY['2025-01','2025-02','2025-03']) AS month
)
SELECT s.*
FROM sales s
INNER JOIN month_rule r
ON s.month = r.month;結論
在資料分析的世界裡,SQL 不只是查資料的工具,它同時也是「邏輯建模」與「效能思維」的體現。一開始我只想著讓需要的資料完整呈現;雖然考慮到日後的維護成本而在程式中加了許多註解(說明未來如何修改),但我忽略了「系統效能」的問題。
我在建構資料時,花最多時間在思考資料如何有效率地組合。有了「想法」,是否用對「方法」同樣重要。如何把「想」與「做」更好地結合,而不是只埋頭苦幹,是我仍需持續學習的;也因此寫下這篇文章,用較易理解的方式記錄與反思,也希望能幫助其他非程式背景的人。
在我與 Cursor、ChatGPT 的合作模式中,雖然最後卡關是由 AI 協助突破,但我仍一步一步追問每段程式的用途與必要性;而不是讓 AI 工具產出後就把任務封存。討論完的結果,我仍然花些時間再把程式調整的更簡單一些,畢竟「AI程式高手」用了許多的「技巧」,但實際上並不需這些複雜的程式執行,並且加上一些日後維護的註解,以利他人也可以修改。
最後,我會請 AI 說明思考流程、並圖像化呈現,加速理解那些過程中未曾想到的面向,並且透過我的理解,再將重點重新整理。許多程式專有名詞,也成了我持續學習的一部分。
這段經驗也讓我反思:下一次看到一堆 UNION ALL 時,
或許可以問自己一句:「這些邏輯能不能變成一張 JOIN 規則表?」
| 重點 | 反思 |
|---|---|
| 資料思維 | 我先分析原始邏輯的共通性,把多段 UNION 裡重複的規則歸納出來。這其實是一種資料建模的思考,把「版本規則」抽象化成維度表的概念。 |
| 效能優化 | UNION ALL 每段都掃主表一次,而 JOIN 模式只掃一次。對百萬級資料的表特別顯著。 |
| 可維護性 | 用 CTE 模組化之後,每個部分邏輯清楚、可重用,後續若要改「預測期長短」或「版本數量」,只改 CTE 即可。 |
| 跨部門價值 | 報表查詢速度變快、穩定性提升,使用者能更快拿到決策資料,也降低 ETL(Extract / Transform / Load) 排程延遲的風險。 |